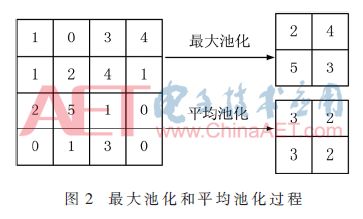
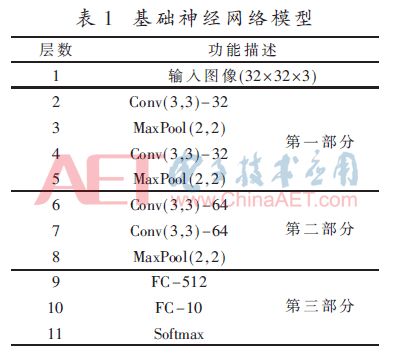
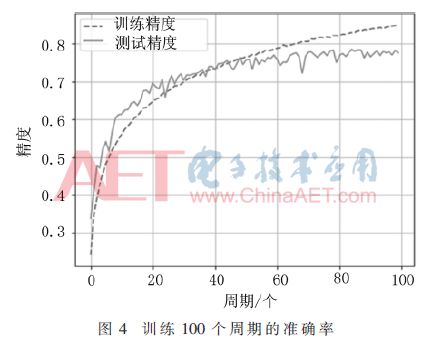
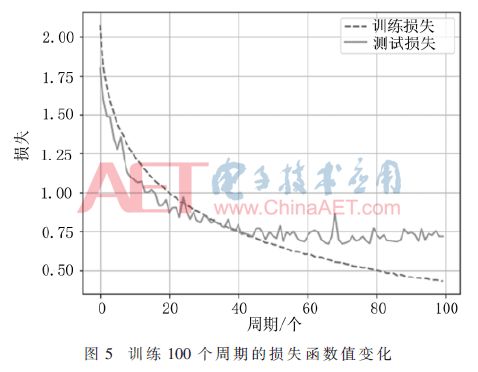
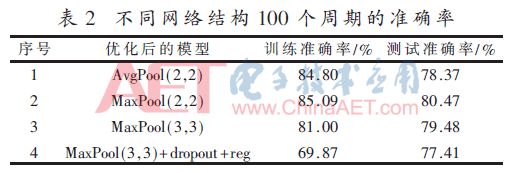
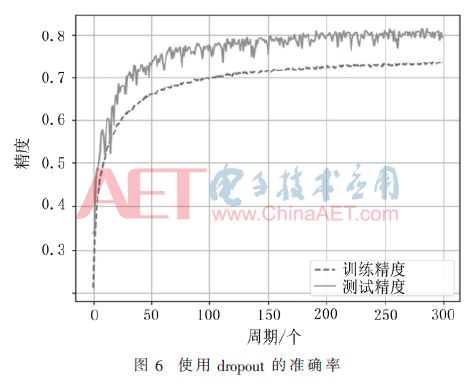
Abstract: A convolutional neural network for image classification is proposed. The influence of different pooling methods on image classification is analyzed and compared. Overlap pooling and dropout technology are used to better solve the problem of overfitting. Compared with the traditional neural network, this method has obtained better results on the CIFAR-10 data set, and the accuracy rate on the test set is about 9% higher than that on the training set. 0 Preface With the rapid development of the Internet and multimedia technologies, image data has shown explosive growth. How to efficiently classify and retrieve massive images has become a new challenge. Image classification is the basis of applications such as image retrieval, object detection and recognition, and is also a research hotspot in pattern recognition and machine learning. Deep learning is a method of characterizing and learning data [1]. It originated from neural networks and has been around for decades, but its development was slow at one time. Until 2012, HOMTPM G and his team achieved excellent results in the ImageNet large-scale image recognition competition, reducing the top-5 error rate from 26% to 15%. Since then, deep learning has attracted more and more researchers. The attention of China has entered a period of rapid development. Deep learning technology often causes over-fitting problems during neural network model training. The so-called overfitting (Overfitting) means that the model fits the data of the training set very well, but it does not fit well to the data set that it has not learned, and its generalization ability is weak, that is, the effect of the learned sample Very good, it does not perform well when generalized to more general and universal samples. Aiming at the common over-fitting problems in neural network models, this paper analyzes and compares the effects of different pooling methods on image classification, and proposes a convolutional neural network using overlapping pooling and dropout technology, which can be relieved to a certain extent In addition to the over-fitting problem, it can cope with more complex and changeable data environments. 1 Convolutional neural network Convolutional Neural Network (CNN) is one of the most commonly used network models for deep learning and is widely used in speech analysis, image recognition and other fields. The traditional neural network is fully connected, the number of parameters is huge, and the training is time-consuming or even difficult to train, while the convolutional neural network is inspired by modern biological neural networks, which reduces the complexity of the model and reduces the weights through local connections and weight sharing. Quantity reduces the difficulty of training. 1.1 Convolutional feature extraction Image convolution is actually a spatial linear filtering of images. Filtering is a commonly used method for frequency domain analysis, and spatial filtering is often used for image enhancement. The filter used for filtering is also the convolution kernel in convolution, which is usually a neighborhood, such as a 3×3 matrix. The convolution process is to sequentially multiply and sum the elements in the convolution kernel with the corresponding pixels in the image as the new pixel value after convolution, and then translate the convolution kernel along the original image to continue to calculate the new pixel value. Until the entire image is covered. The convolution process is shown in Figure 1. Figure 1 is the convolution process ignoring the bias term. The input image size is 5×5, the convolution kernel size is 3×3, and the output size after convolution is also 3×3. The specific calculation process is that the convolution kernel performs linear summation from the upper left corner of the input image, and then moves to the right by a distance of one pixel at a time, until the rightmost, and then moves down by one pixel. Product output. If you want the output and input to have the same size, you can add a circle of "0" around the original image to become 7×7, and then perform convolution. Although the process of convolution is very simple, it can produce many different effects on the image according to different convolution kernels. The above convolution process is essentially a correlation effect, which is slightly different from convolution in strict image processing. Strict convolution requires the convolution kernel to be rotated by 180° before performing correlation operations. The convolution operation of the image is actually the feature extraction of the image. Convolution can eliminate the influence of image rotation, translation and scale transformation [2]. Convolutional layers are particularly good at extracting features from image data, and different layers can extract different features. Convolutional neural networks are characterized by extracting features layer by layer. The first layer extracts features at a lower level, and the second layer continues to extract higher-level features on the basis of the first layer. Similarly, the third layer is based on the second layer. The features extracted above are also more complex. The more advanced features can reflect the category attributes of the image, and the convolutional neural network extracts the excellent features of the image by layer-by-layer convolution. 1.2 Pooling down sampling After the image is convolved, multiple feature maps will be generated, but the size of the feature map has not changed compared with the original image. The amount of data is still large, and the amount of calculation is also large. In order to simplify the operation, the feature map is often downloaded sampling. Convolutional neural networks use pooling for down-sampling. There are two common pooling methods: MaxPooling and AvgPooling. The two pooling processes are shown in Figure 2. Show. In Figure 2, the window size is 2×2, and the step size is 2. Maximum pooling is to select the largest pixel value in the 4 pixels covered by the window as the sample value; average pooling is to calculate the average value of 4 pixels in the window, each time the window is moved 2 pixels to the right or down Therefore, the size of the 4×4 feature map becomes 2×2 after pooling. 2 CNN model design for image classification This paper refers to the idea of ​​convolution block in VGGNet [3] and designs a convolutional neural network model. The dropout layer is added to the convolutional layer and the fully connected layer, which alleviates the over-fitting problem to a certain extent. It also supports different pooling methods. The effect of the pooling window on the classification effect was analyzed and compared. 2.1 Basic neural network structure The network model is shown in Table 1. There are 11 layers, including 4 convolutional layers, 3 pooling layers, and mainly 3 parts. First of all, the first layer is the input layer. There are 10 types of data sets used in this article, which are color images with a size of 32×32. The RGB color space is used, so the input layer size is 32×32×3. The first part includes 2 convolutional layers and 2 pooling layers, and the number of feature maps of the 2 convolutional layers is 32; the second part includes 2 convolutional layers and 1 pooling layer, with 2 convolutional features The graphs are all 64; the third part is the densely connected layer, that is, the fully connected layer, the first fully connected layer has 512 neurons, the second layer has 10, that is, it is divided into 10 categories, and then used Softmax regression classification. Conv(3,3)-32 in Table 1 represents that the layer is a convolutional layer, and the size of the convolution kernel is 3×3 with 32 feature maps; MaxPool(2,2) refers to the maximum pooling, and the window The size is 2×2; FC-512 means that this layer is a fully connected layer, and the number of neurons is 152. 2.2 Analysis of existing problems For this model, the CIFAR-10 data set is used for experimental testing. Some examples are shown in Figure 3. Use the CIFAR-10 data set combined with the Rmsprop optimization method to train the network, and train all the images in the training set into an epoch. After 100 cycles of training, the accuracy of the training process changes as shown in Figure 4. In each cycle of the training process, the accuracy of the training data set and the test data set is calculated. It can be seen that before 40 cycles, the accuracy of the test set increases with the accuracy of the training set. At the 40th cycle Reached 0.74; after that, the accuracy of the training set continued to rise, while the accuracy of the test set rose very little, and there were small fluctuations; after 70 cycles, the accuracy of the training set continued to rise, while the accuracy of the test set remained stable and changed Very small. The loss function of this training is shown in Figure 5. It can also be seen from Figure 5 that at the beginning, the test set decreased with the loss value of the training set. After 40 cycles, the loss value of the test set has been fluctuating between 0.72 and 0.75, while the loss value of the training set has been maintained. In the downward trend, the 80th cycle dropped to 0.50 and finally to 0.42. The change of the loss function also confirms from the side that the model has a serious overfitting problem. 3 Model proposed in this article Using overlapping pooling can alleviate the over-fitting problem, and using regularization can also solve the over-fitting problem. HINTON GE proposed the dropout technology [4] in 2012, which greatly improved the over-fitting problem of neural networks. Dropout refers to randomly discarding some neurons according to a certain proportion in the process of training the network, that is, randomly selecting a part of the neurons in a layer to make the output value 0, which will make this part of the selected neurons to the next The output of the neurons connected to the layer does not contribute and loses its function. Many experiments have found that the maximum pooling effect for this network model is relatively better than the average pooling effect. The use of overlapping pooling can also improve the effect. The accuracy of the training set and test set for 100 cycles is shown in Table 2. Table 2 records the highest accuracy rates of the training set and the test set in 100 cycles for different network structures. The first and second models use the average and maximum non-overlapping pooling respectively. It can be seen that the maximum pooling is better than the average pooling, but both have the problem of overfitting; the third The model is the maximum overlap pooling, which alleviates the overfitting problem to a certain extent; the fourth model uses the maximum overlap pooling and dropout technology and adds an appropriate amount of regularization. It can be seen that the accuracy of the training set is far lower For the test set, there is still greater potential for its accuracy to increase. Therefore, the fourth type is selected as the optimized network structure. The complete network structure is shown in Table 3. Compared with the original structure, the optimized network structure adds a 0.25 ratio dropout layer after the 5th and 9th maximum overlap pooling layers, and a 0.5 ratio dropout layer after the 11th fully connected layer. In addition, L2 regularization is used for the network weights of the convolutional layer and the fully connected layer. The regularization factor is as small as 0.0001, and the accuracy after 300 cycles of training using the Rmsprop learning method is shown in Figure 6. It can be seen from the training process in Figure 6 that the dropout technology solves the overfitting problem better. The accuracy of the test set increases with the accuracy of the training set, and the accuracy of the training set has always been lower than the test set, 300 The highest accuracy rate of the training set during the cycle is 73.49%, and the highest accuracy rate of the test set can reach 82.15%. It can be seen that the dropout technology greatly improves the over-fitting problem. Dropout randomly discards some neurons during the training process. Each batch of data is trained with a different network structure, which is equivalent to training multiple networks, combining multiple networks with different structures, and integrating multiple trainings The integrated network can effectively prevent the over-fitting of a single-structure network. 4 Conclusion This paper proposes a convolutional neural network model for image classification. Aiming at the over-fitting problem of traditional convolutional neural networks, different pooling methods and dropout technologies are used to optimize the network structure and improve the image classification of the model. Performance, achieved better classification results on the CIFAR-10 data set.
FOLI has many types of disposables vape; FOLI BOX is one of popular Disposable Vape.
5000 Puffs, Mesh Coil, good cigarette oil, good, tasty and the price is reasonable. The minimum order quantity is 30 pieces, in stock, and delivered on the same day. It only takes 7-10 days from China to destination. Please take an order if you are interested.
Foli Vape is a hot vape brand in many countries. Foli Disposable Vape provides an innovative leak-resistant maze coil, ensuring security wherever you are and regardless of your daily activities.Foli Box disposable vape is rich in flavors, with 16 taste choices. The bottom suction resistance adjustment button can adjust the suction resistance according to personal preference.FOLI Box disposable vape is bright and colourful, and is deeply loved by young people.
Foli Disposable Vape,Big Smoke High-Power Vape,E Cigarette Atomizer ,Disposable Vape Mash Coil TSVAPE Wholesale/OEM/ODM , https://www.tsecigarette.com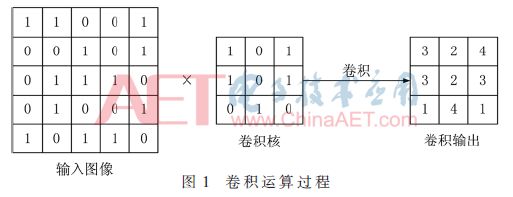


Disposable Vape FOLI BOX 12ml 5000 Puffs Big Smoke rechargeable
600mah A-level battery
12ml eujice & 1.2ohm
16 flavors available Outstanding Flavor
Nicotin 3%
Puffs: 5000 Puffs
Volume:12ml
Battery Capacity:600mAh
Charging Port:Type-C
Suction resistance adjustment button
Flavor List:
MINT
LYCHEE STRAWBERRY
GREEN APPLE
WATERMELON
ORANGE MANGO
STRAWBERRYICECREAM
CRANBERRYGRAPE
GRAPE
BLUEBERRYRASPBERRY
LEMON TEA
BANANA LYCHEE
SKITTLES
GOLDEN FRUIT
BLUEBERRY
WATERMELON LYCHEE
STRAWBERRY
Features
1. No other carcinogenic substance.
2. Harmless to others and the environment. With no danger of second-hand smoking.
3. Smoke in public places, business, restaurants, planes etc. Does not emit any smell.
4. Enable smokers to abstain from smoking non-painfully.
5. Save the smoking cost of nearly 80% each year.
6. No ignition and no fire danger.



